How to make a voice to AI image generator

Daily Disco
What are we building?
Today, we will be building a voice to AI image generator.
The tech stack that we will be using is Next JS for our frontend, mic-to-mp3-recorder npm package, Docker, OpenAI's APIs, and a bit of Python for the backend.
Project Set up
Let's create a new folder on our desktop named, "voice-to-img-generator".
Open this folder in VS Code.
Inside this folder create two more folders named backend and frontend.
Set up Backend Environment
First head into the backend directory by typing cd backend in the terminal.
Make sure that you have Python install and set up with Pyenv. (3.7 or higher).
Create our, "requirements.txt", file. This is where we will list all the packages that we need to download:
replicate python-dotenv flask_cors openai torch flask mangum pydub speechrecognition
Now in the Python terminal, run pip3 install -r requirements.txt. This will install all our packages.
Now let's create two more files inside our backend folder.
First, the file named Dockerfile. (Make sure that you Docker installed on your PC and running. We will be creating a Docker script to "dockerize" our project's environment.)
Set up your Dockerfile as follows:
FROM python:3.10-slim WORKDIR /python-docker COPY requirements.txt requirements.txt RUN apt-get update && apt-get install git -y RUN pip3 install -r requirements.txt RUN pip3 install "git+https://github.com/openai/whisper.git" RUN apt-get install -y ffmpeg COPY . . EXPOSE 5000 CMD [ "python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Then create the app.py create a Python script and flask API endpoint that will run and fetch the audio, and then pass the text to the AI image generator.
First, let's import all our packages:
import torch import os import replicate import openai from dotenv import load_dotenv import webbrowser from flask import Flask, abort, request from flask_cors import CORS from tempfile import NamedTemporaryFile import whisper import gpt3
Next, let's create the Flask app, set up CORS settings, and the .env + secret key. (You can get the secret key for Replicate from Replicate.com.)
app = Flask(__name__)
CORS(app, supports_credentials=True)
load_dotenv()
replicate.api_key = os.getenv("REPLICATE_API_KEY")Next, we will check if an NVIDIA GPU is available to run the models. Then we will add the Whisper and Replicate models:
# Check if NVIDIA GPU is available
torch.cuda.is_available()
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load the Whisper model:
model = whisper.load_model("base", device=DEVICE)
# Load the Replicate model:
replicate = replicate.models.get("stability-ai/stable-diffusion")Here's where we will begin creating our API end point, with Flask, by creating a route:
@app.route('/whisper_mic', methods=['POST', 'GET'])Now, inside this route, let's create a function that will contain all our logic:
def generate_whisper_mp3():
Create an empty array to hold everything:
results = []
Let's create a function so that we can loop through the files that the user has submitted. We will also be passing the audio file to the Whisper model, and then the text results to the Replicate model. Lastly, we will print the first picture, and open the web browser to that picture:
for filename, handle in request.files.items():
# Create a temporary file.
# The location of the temporary file is available in `temp.name`.
temp = NamedTemporaryFile()
# Write the user's uploaded file to the temporary file.
# The file will get deleted when it drops out of scope.
handle.save(temp)
# Let's get the transcript of the temporary file.
result = model.transcribe(temp.name)
text = result['text']
# Replicate Image Generation
# replicate = replicate.models.get("stability-ai/stable-diffusion")
output_url = replicate.predict(prompt=text)[0]
print(output_url)
webbrowser.open(output_url)Now, let's append all our results onto an object. We will have the filename, transcript, text, and the output URL of the image:
for filename, handle in request.files.items():
# Create a temporary file.
# The location of the temporary file is available in `temp.name`.
temp = NamedTemporaryFile()
# Write the user's uploaded file to the temporary file.
# The file will get deleted when it drops out of scope.
handle.save(temp)
# Let's get the transcript of the temporary file.
result = model.transcribe(temp.name)
text = result['text']
# Replicate Image Generation
# replicate = replicate.models.get("stability-ai/stable-diffusion")
output_url = replicate.predict(prompt=text)[0]
print(output_url)
webbrowser.open(output_url)
# # Let's get the summary of the sound file
# summary = gpt3.gpt3complete(text)
# # Let's make a summary of the first summary
# secondSummary = codex.codexComplete(summary)
# Now we can store the result object for this file.
results.append({
'filename': filename,
'transcript': result['text'],
'output_url': output_url,
# 'summary': summary.strip(),
# 'secondSummary': secondSummary.strip(),
})Lastly, let's return the results as a JSON object that we will pass to our frontend:
@app.route('/whisper_mic', methods=['POST', 'GET'])
def generate_whisper_mp3():
# print('Hello world!', file=sys.stderr)
# if not request.files:
# # If the user didn't submit any files, return a 400 (Bad Request) error.
# abort(400)
# For each file, let's store the results in a list of dictionaries.
results = []
# Loop over every file that the user submitted.
for filename, handle in request.files.items():
# Create a temporary file.
# The location of the temporary file is available in `temp.name`.
temp = NamedTemporaryFile()
# Write the user's uploaded file to the temporary file.
# The file will get deleted when it drops out of scope.
handle.save(temp)
# Let's get the transcript of the temporary file.
result = model.transcribe(temp.name)
text = result['text']
# Replicate Image Generation
# replicate = replicate.models.get("stability-ai/stable-diffusion")
output_url = replicate.predict(prompt=text)[0]
print(output_url)
webbrowser.open(output_url)
# # Let's get the summary of the sound file
# summary = gpt3.gpt3complete(text)
# # Let's make a summary of the first summary
# secondSummary = codex.codexComplete(summary)
# Now we can store the result object for this file.
results.append({
'filename': filename,
'transcript': result['text'],
'output_url': output_url,
# 'summary': summary.strip(),
# 'secondSummary': secondSummary.strip(),
})
# This will be automatically converted to JSON.
return {'results': results}Nice, we are now done with our backend:
Set up Frontend Environment
Now let's head out of our backend folder and head into the frontend by heading to the root directory with cd .. in the terminal followed by cd frontend.
Run npx create-next-app@latest in the terminal to create the Next JS app in our directory.
Then run npm install mic-to-mp3-recorder to install our browser mic that will grab the audio.
Now, inside the root of the frontend folder, create a components folder. Then add two files to the components folder AiImage.jsx and Microphone.jsx.
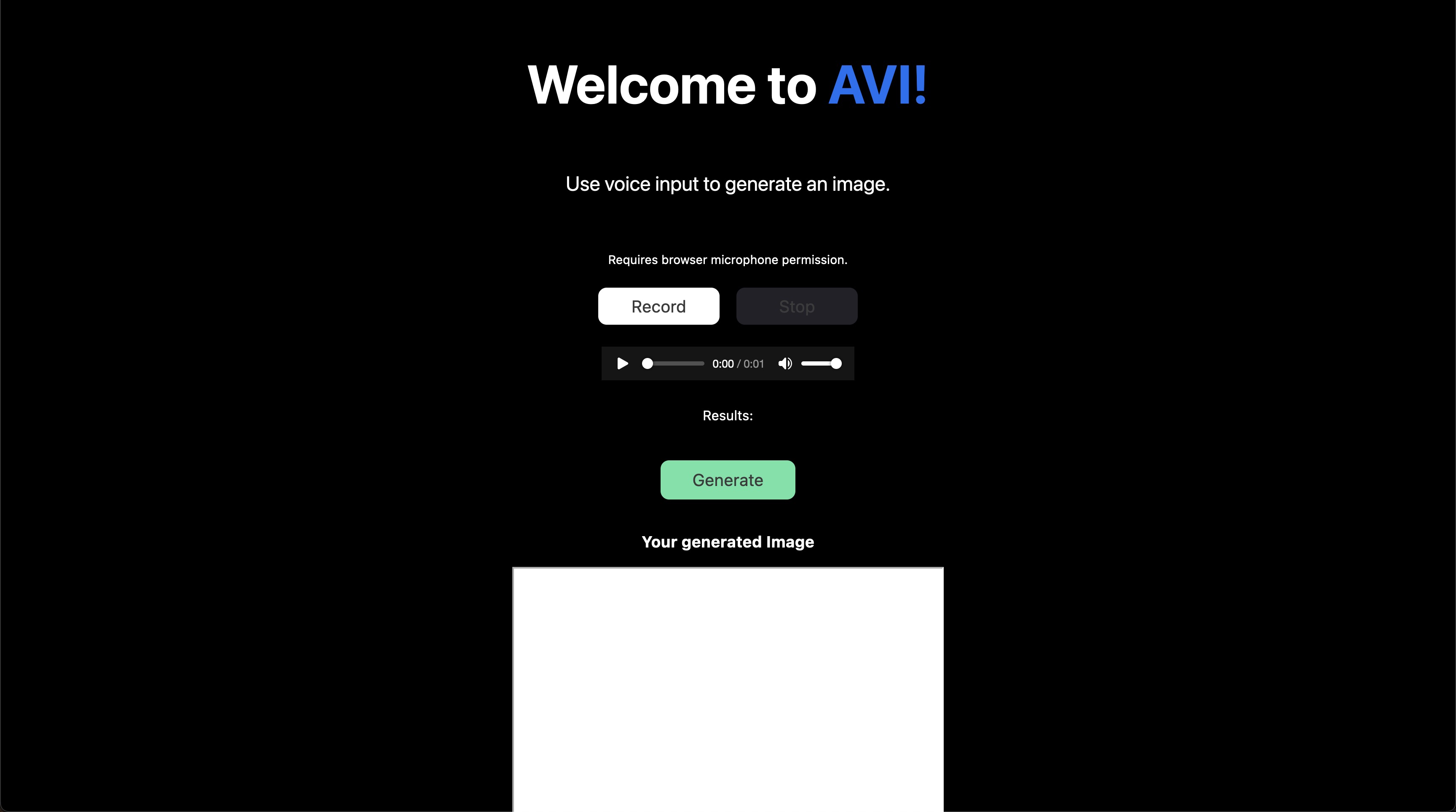
Create the AiImage.jsx code as follows:
import React from 'react';
const Whisper = ({ transcript, micTranscript, replicate }) => {
return (
<div className='text-output'>
<h3>Your generated Image</h3>
<div className='large-box'>
<iframe src={replicate} height={512} width={512}></iframe>
</div>
</div>
);
};
export default Whisper;Create the Microphone.jsx code as follows:
import React from 'react';
import styles from '../styles/Home.module.css';
const Microphone = ({
isRecording,
isBlocked,
startRecording,
stopRecording,
blobURL,
loading,
micTranscript,
handleSubmit,
audio,
}) => {
return (
<div className='live-recording'>
<p className={styles.description}>
{' '}
Use voice input to generate an image.{' '}
</p>
{isRecording ? (
<p className={styles.warning}> Recording in progress... </p>
) : (
<p className={styles.warning}>
{' '}
Requires browser microphone permission.{' '}
</p>
)}
{isBlocked ? (
<p className={styles.blocked}> Microphone access is blocked. </p>
) : null}
<div className={styles.whispercontainer}>
<div className={styles.allbuttons}>
<button
onClick={startRecording}
disabled={isRecording}
className={styles.recordbutton}
>
Record
</button>
<button
onClick={stopRecording}
disabled={!isRecording}
className={styles.stopbutton}
>
Stop
</button>
</div>
<div className={styles.audiopreview}>
<audio src={blobURL} controls='controls' />
</div>
<div className={styles.loading}>
{loading ? (
<p>Loading... please wait.</p>
) : (
<p>Results: {micTranscript}</p>
)}
</div>
<div className={styles.generatebuttonroot}>
<button
type='submit'
className={styles.generatebutton}
onClick={handleSubmit}
disabled={!audio}
>
Generate
</button>
</div>
</div>
</div>
);
};
export default Microphone;
Create the index.js code by importing all the packages, declaring your states, and adding the recording functions. Lastly, set up the API fetch to our Flask API in the handleSubmit() function:
import React, { useState, useEffect, useMemo } from 'react';
import styles from '../styles/Home.module.css';
import Head from 'next/head';
import Image from 'next/image';
import Microphone from '../components/Microphone';
import MicRecorder from 'mic-recorder-to-mp3';
import Header from '../components/Header';
import AImage from '../components/AImage';
export default function Home() {
const [micTranscript, setMicTranscript] = useState(null);
// const [loading, setLoading] = useState(false);
const [audio, setAudio] = useState();
const [isRecording, setIsRecording] = useState(false);
const [blobURL, setBlobURL] = useState('');
const [isBlocked, setIsBlocked] = useState(false);
const [replicate, setReplicate] = useState(null);
const recorder = useMemo(() => new MicRecorder({ bitRate: 128 }), []);
const startRecording = () => {
if (isBlocked) {
console.log('Permission Denied');
setIsBlocked(true);
} else {
recorder
.start()
.then(() => {
setIsRecording(true);
console.log('recording');
})
.catch((e) => console.error(e));
}
};
const stopRecording = () => {
setIsRecording(false);
console.log('stopped recording');
recorder
.stop()
.getMp3()
.then(([buffer, blob]) => {
const file = new File(buffer, 'test.mp3', {
type: blob.type,
lastModified: Date.now(),
});
setBlobURL(URL.createObjectURL(file));
// Convert to base64
const reader = new FileReader();
reader.readAsDataURL(file);
reader.onloadend = function () {
setAudio(file);
console.log('audio', audio);
};
});
};
const handleSubmit = async (e) => {
e.preventDefault();
setIsRecording(false);
// setLoading(true);
const formData = new FormData();
formData.append('audioUpload', audio);
console.log('using this file', audio);
const audioFile = audio;
console.log('audioFile', audioFile);
console.log('requesting api');
fetch('http://127.0.0.1:5000/whisper_mic', {
method: 'POST',
headers: {
// 'Content-Type': 'application/json',
},
body: formData,
})
.then((res) => res.json())
.then((data) => {
console.log(data);
return data;
})
.then((data) => {
// loop through the data to turn it into an array
const arr = Object.keys(data).map((key) => data[key]);
console.log(arr);
setMicTranscript(arr[0][0].transcript);
console.log(micTranscript);
setReplicate(arr[0][0].output_url);
console.log(arr[0][0].output_url);
console.log(replicate);
// setSummary(arr[0][0].summary);
// setSecondSummary(arr[0][0].secondSummary);
// console.log(summary);
// console.log(secondSummary);
})
.then((result) => {
console.log('Success:', result);
})
.catch((error) => {
console.error('Error:', error);
});
};
return (
<div className={styles.container}>
<Head>
<title>Create Next App</title>
<meta name='description' content='Voice to Image AI Generator' />
</Head>
<main className={styles.main}>
<Header />
<Microphone
isRecording={isRecording}
isBlocked={isBlocked}
startRecording={startRecording}
stopRecording={stopRecording}
blobURL={blobURL}
micTranscript={micTranscript}
handleSubmit={handleSubmit}
audio={audio}
/>
<AImage replicate={replicate} />
</main>
</div>
);
}Lastly, let's set up our CSS.
Testing
Make sure that you have two terminals open, one for the backend and one for the frontend.
Then, in the backend folder, we are going to run the following commands to build the docker image and start the server.
docker build -t voice-to-image .
docker run -dp 5000:5000 voice-to-image
Now, in the frontend folder, run npm run dev to start the frontend.
Head over to your localhost:3000 in your web browser, and you should be able to go ahead and input some audio and get your results!
If you're running into any issues, feel free to leave a comment, or try to debug with console.logs and the browser terminal.
Thanks for taking the time to read this, more to come.
Future Features
Production Build
Voice to Image Video AI
Daily Disco
The Daily Disco is your source for AI tutorials and tech talks. Don't forget to subscribe to be notified of new posts!